Learn how a data mesh aligns data management with domain expertise, enhancing overall organizational agility.
Introduction
Have you faced challenges in managing decentralized data across various business units or domains? Implementing a Data Mesh can address these issues, aligning data management with domain expertise and enhancing your organization’s overall agility. In this post, we'll explore what a Data Mesh is, why it's beneficial, and how to implement it effectively within your organization.
What is Data Mesh?
Data Mesh is a decentralized data architecture that shifts the responsibility of data management from a central team to individual business units, or "domains." Each domain in turn produces “data products”, or consumable data artifacts, ensuring that data management is closely aligned with domain-specific expertise. This approach promotes agility, scalability, and the ability to generate insights more effectively.
If you’re familiar with Service-Oriented Architectures, i.e. micro-services, this might sound familiar. Data Mesh is a somewhat analogous concept, but applied to data!
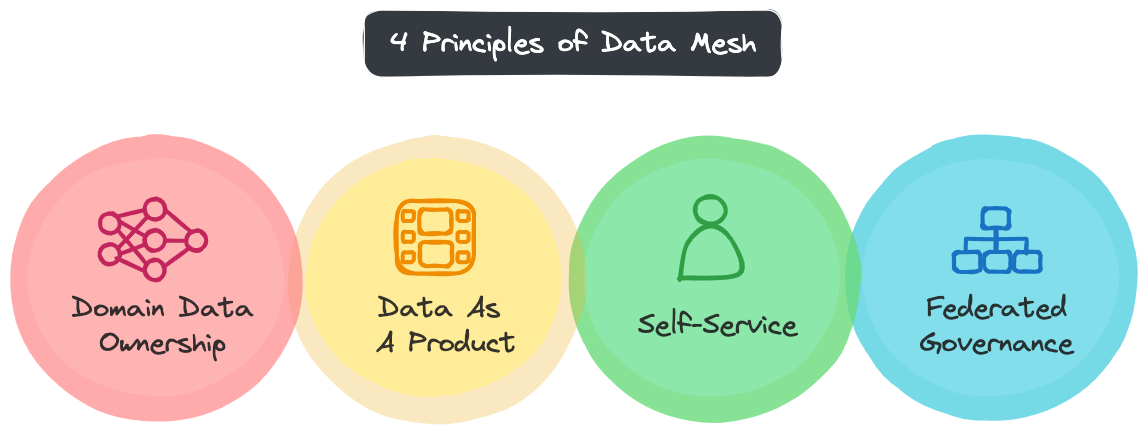
4 Principles of Data Mesh
| Principle | Explanation |
|---|---|
| Domain Data Ownership | Organizing data into explicit domains based on the structure of your organization, and then assigning clear accountability to each. This enables you to more easily increase the number of sources of data, variety of use cases, and diversity of access models to the data increases. |
| Data as a product | Domain data should be highly accessible and highly reliable by default. It should be easy to discover, easy to understand, easy to access securely, and high quality. |
| Self-Service | Domain teams should be able to independently create, consume, and manage data products on top of a general-purpose platform that can hide the complexity of building, executing and maintaining secure and interoperable data products. |
| Federated Governance | Consistent standards that are enforced by process and technology around interoperability, compliance, and quality. This makes it easy for data consumers to interact with data products across domains in familiar way and ensures quality is maintained uniformly. |
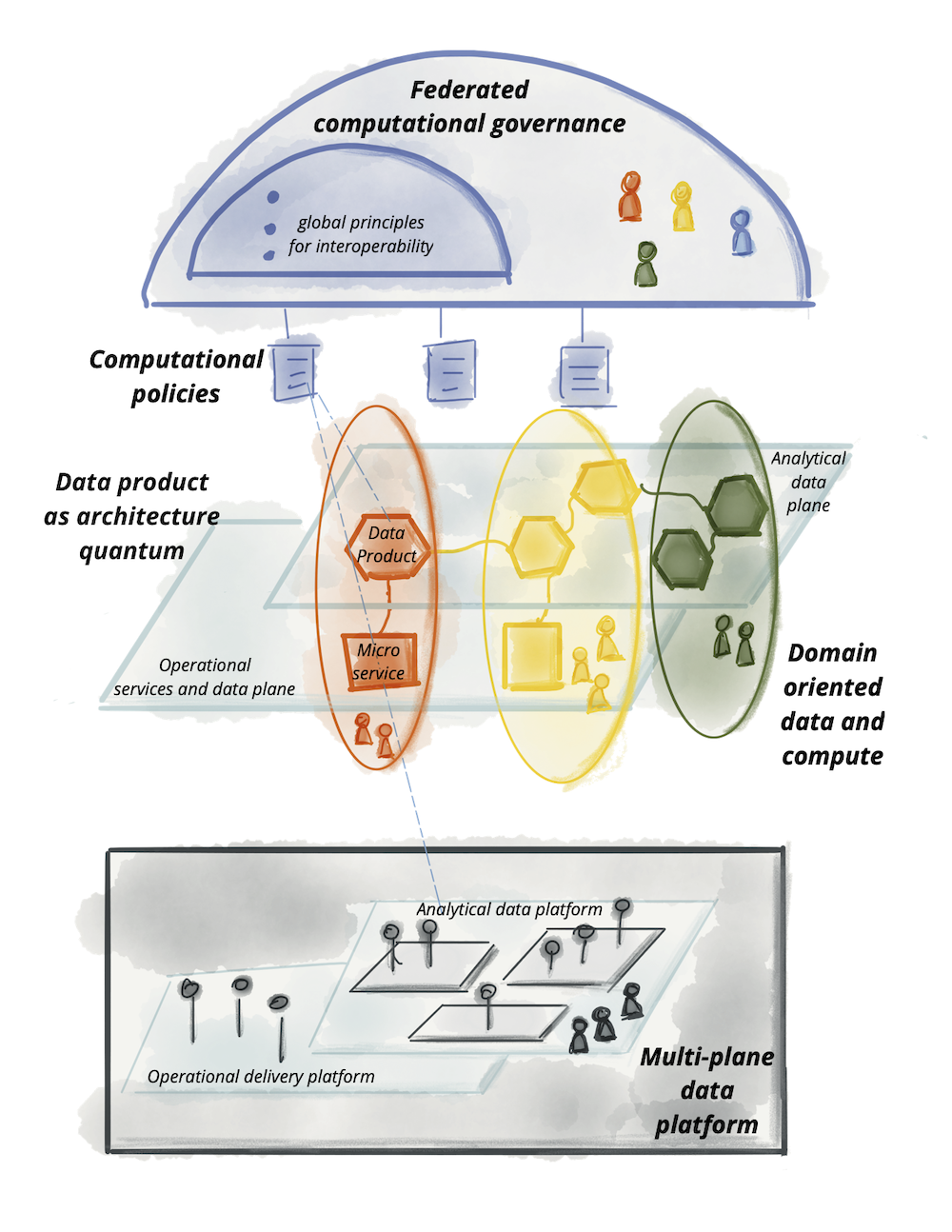
Logical architecture of data mesh approach, Image Credit: Zhamak Dehghani
Why Implement Data Mesh?
For data architects and data platform leads, implementing a Data Mesh can resolve various challenges associated with managing decentralized data, particularly as you try to scale up.
Traditional data lakes or warehouses can become central bottlenecks, impairing access, understanding, accountability, and quality of data - ultimately, its usability. These architectures can struggle to meet the diverse needs of different business units, leading to inefficiencies.
Data Mesh addresses these issues by formally dividing data into decentralized domains, which are owned by the individual teams who are experts in those domains. This approach allows each business unit or domain to manage its own data, enabling independent creation and consumption of data and increasing the agility, reliability, scalability of an organization’s data practice.
Key Considerations for Your Organization
Decentralized Data Management: Have you experienced difficulties or bottlenecks in managing data across various business units? Implementing a Data Mesh can alleviate these issues by allowing each domain to build and share its own data products, enhancing agility and scalability.
Overcoming Centralized Bottlenecks: If your organization relies on a centralized data lake or warehouse, or data platform team, have you encountered limitations in scalability or delays in data access and analysis? Data Mesh can help overcome these bottlenecks by “pushing down” data ownership and management to domain experts.
Enhancing Agility and Reliability: How important is it for your organization to respond quickly to market changes and generate insights reliably? By formally defining the responsibilities around data “products”, a data mesh architecture can provide the flexibility and speed needed to stay competitive.
How to Implement Data Mesh
Implementing Data Mesh doesn’t need to be a headache. Here’s how your organization can move towards a better future:
Best Practices and Strategies
Define Domains and Data Products
Formally define the different business units or domains within your organization and define the data products each domain will own and manage, and then begin to organize the data on your existing warehouse or lake around these domains. This ensures clarity and responsibility for data management.
Establish Clear Contracts
Create a clear set of expectations around what it means to be a domain or data product owner within your organization. Then, build processes and systems to both reinforce and monitor these expectations. This helps maintain consistency and reliability across the organization.
Monitor Data Quality
Use metadata validation and data quality assertions to ensure that your expectations are being met. This includes setting standards for both data quality - freshness, volume, column validity - as well compliance with your less technical requirements - ownership, data documentation, and data classification.
Move Towards Federated Governance
Adopt a federated governance model to balance autonomy and control. While domains manage their data products, a central team can oversee governance standards and ensure compliance with organizational policies via a well-defined review process.
Alternatives
While a centralized data lake or warehouse can simplify data governance by virtue of keeping everything in one place, it can become a bottleneck as your data organization grows. Decentralized Data Mesh can provide a more scalable and agile approach, by distributing day-to-day responsibility for accessing, producing, and validating data while enforcing a centralized set of standards and processes.
Our Solution
Acryl DataHub offers a comprehensive set of features designed to support the implementation of a Data Mesh at your organization:
- Data Domains: Clearly define and manage data products within each business unit.
- Data Products: Ensure each domain owns and manages its data products, promoting autonomy and agility.
- Data Contracts: Establish clear agreements between domains to ensure consistency and reliability.
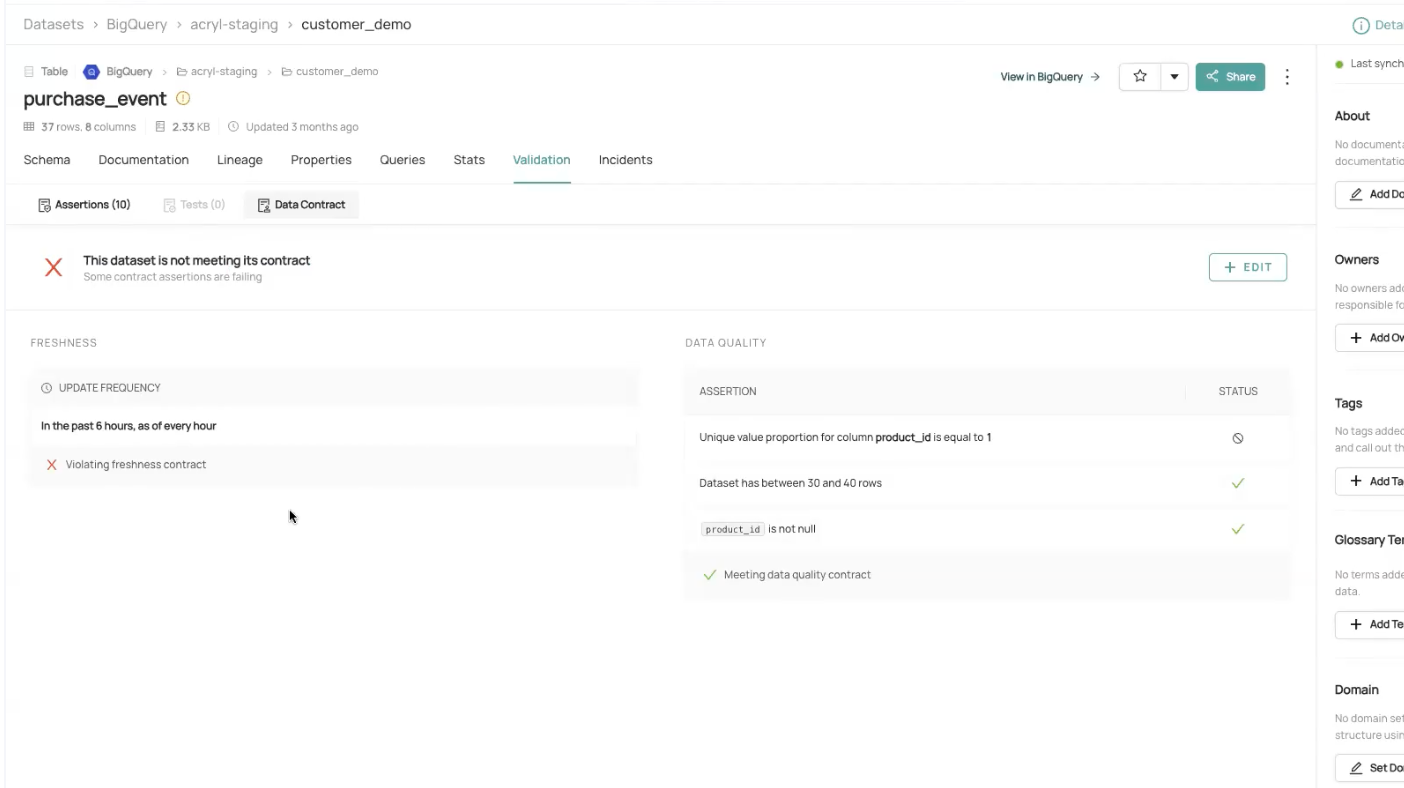
Data Contracts in Acryl DataHub UI
- Assertions Monitor data quality using freshness, volume, column validity, schema, and custom SQL checks to get notified first when things go wrong
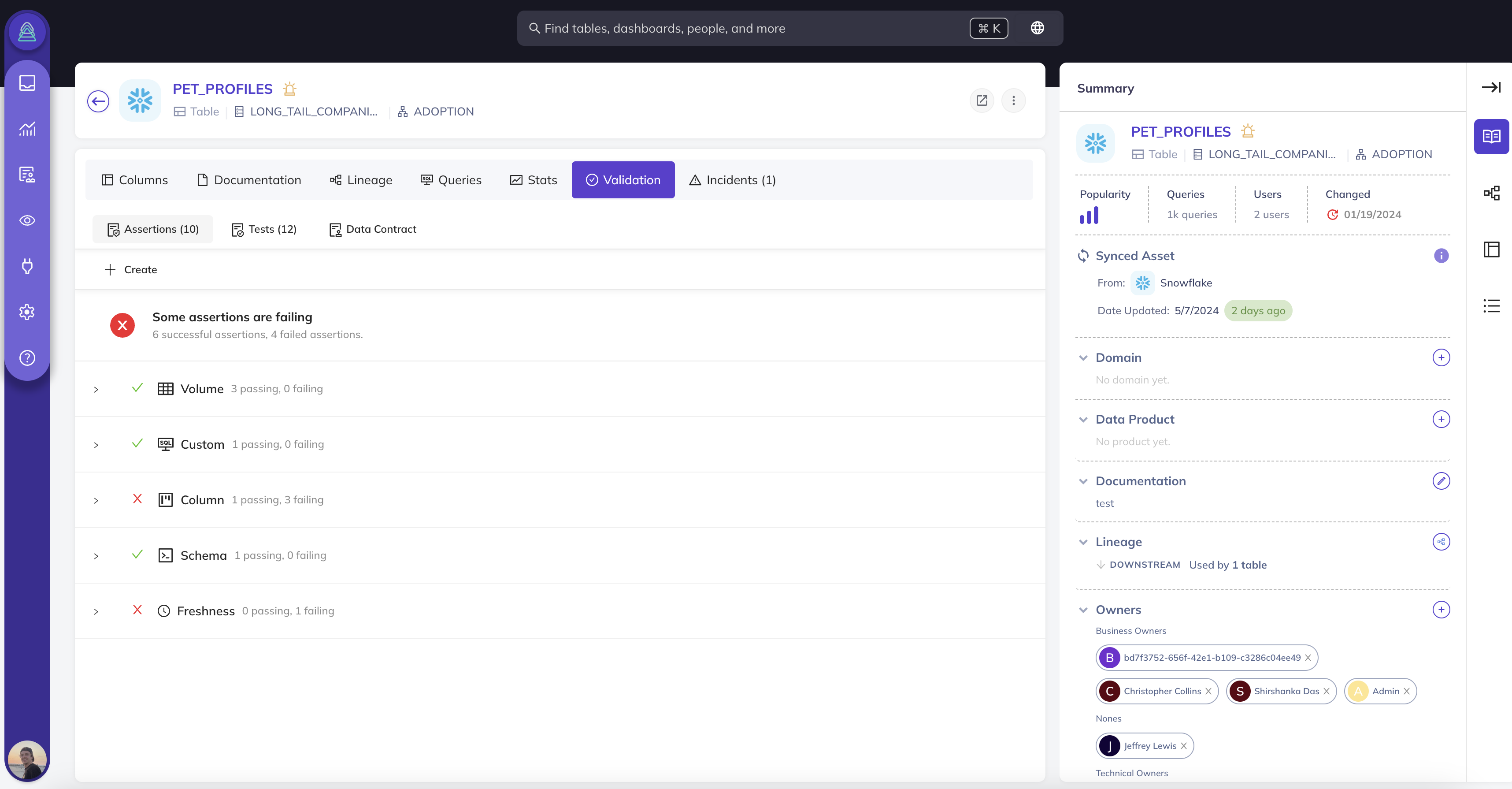
Assertion Results
- Metadata Tests: Monitor and enforce a central set of standards or policies across all of your data assets, e.g. to ensure data documentation, data ownership, and data classification.
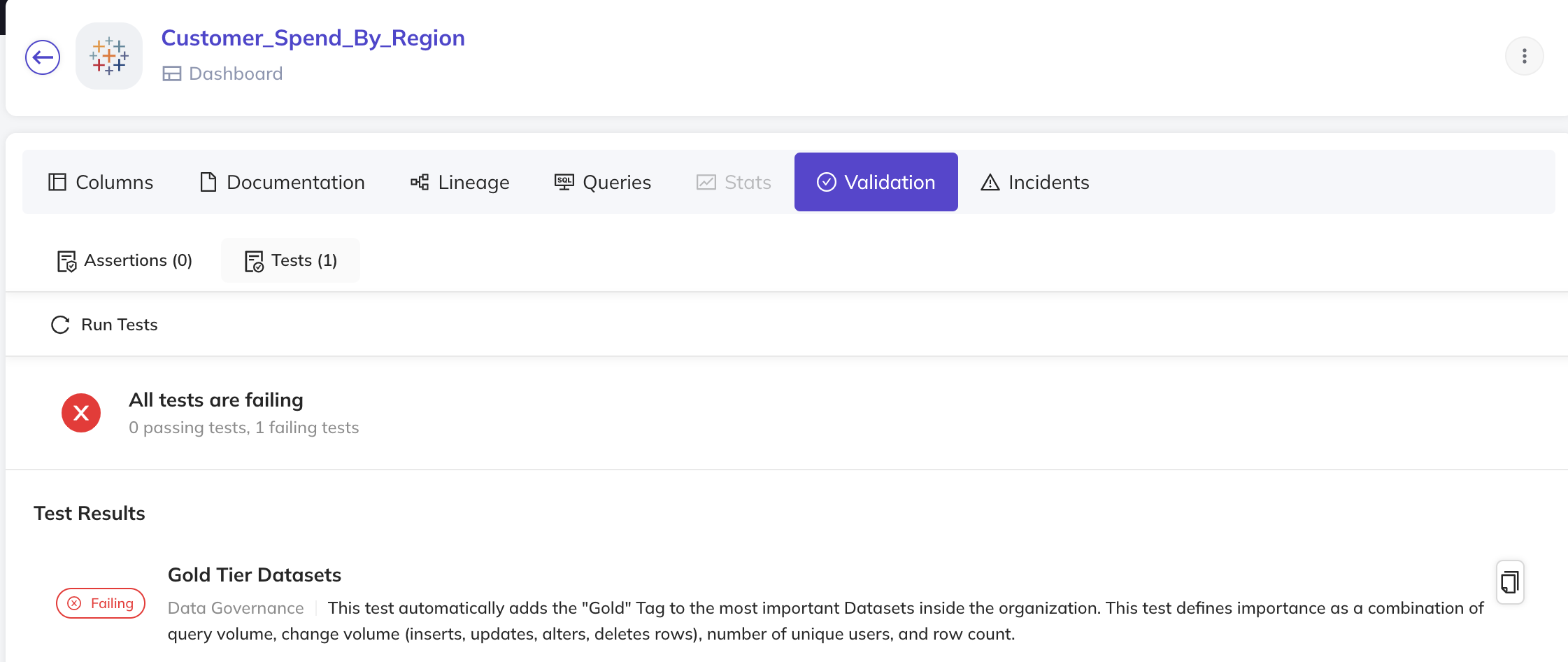
Metadata Test Results
By implementing these solutions, you can effectively manage decentralized data, enhance agility, and generate insights more efficiently.
Conclusion
Implementing a Data Mesh can significantly improve your organization's ability to manage and leverage decentralized data. By understanding the benefits of data mesh and following best practices for implementation, you can overcome the limitations of centralized data systems and enhance your agility, scalability, and ability to generate insights. Acryl DataHub was built from the ground up to help you achieve this, providing the tools and features necessary to implement a large-scale Data Mesh successfully.